ElasticSearch之——WebFlux
3.WebFlux
是不是感觉Elasticsearch的异步API感觉很别扭,而且似乎没什么用处?
那是因为我们之前学习的所有Web程序组件,都是同步阻塞的编程方式。包括:Tomcat、Servlet、SpringMVC、Mybatis等等。
因此在同步阻塞运行大环境下,使用异步API,就难以发挥异步调用的长处。
同步和异步执行,到底有怎样的差异呢?
3.1.同步和异步
那么同步和异步之间究竟有怎样的差异呢?
3.1.1.同步请求
一个典型的请求同步处理过程:
- 1.开启线程,接收用户
- 2.处理业务
- 3.调用DB(比如elasticsearch)
- 4.等待DB返回数据(无效的等待)
- 5.返回数据给用户

3.1.2.异步请求
一个典型的请求异步处理过程:
- 1.开启线程,接收用户
- 2.处理业务
- 3.调用DB(比如elasticsearch)
- 4.不等待,处理其他请求(同时DB准备数据)
- 5.DB返回数据,传递给
异步回调函数 - 6.返回给用户

虽然处理过程麻烦了,但是无疑我们可以同时服务更多请求了,系统的吞吐量得到了提升。
3.1.3.总结
异步执行相对于同步执行,可以大大提高CPU的利用率,减少CPU空置时间,提高服务的吞吐量,但是并不能减少单次请求的执行耗时。
那么,有没有一套可以取代tomcat、SpringMVC,实现异步编程的Web应用方案呢?
3.1.4.异步Servlet(了解)
在Servlet3.0已经支持了异步编程,来看一个同步和异步Servlet的实例。
新建一个web项目,并在其中创建两个servlet:
1)同步运行的servlet
代码:
1 | package cn.itcast.demo.servlet; |
在业务中,休眠3秒来模拟业务的执行。
2)异步运行的Servlet
代码:
1 | package cn.itcast.demo.servlet; |
注意关键点:
asyncSupported:在@WebServlet注解上,通过asyncSupported=true来开启异步支持AsyncContext:通过request.startAsync()来初始化一个AsyncContext对象,并创建异步运行环境。asyncContext.start():通过AsyncContext的start(Runnable task)方法来开启一个异步任务,context.complete():通过context.complete()来标记业务结束
3)测试
启动项目,并分别访问:
1 | localhost:8080/sync |
虽然浏览器返回结果都是耗时3秒:

不过,在服务端AsyncServlet的执行却并没有阻塞:
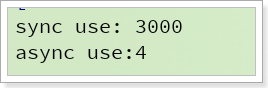
由此可见,异步执行的Servlet不需要阻塞等待任务执行结果,而是处理其它请求,应用的并发能力就得到了提升。
3.2.认识WebFlux
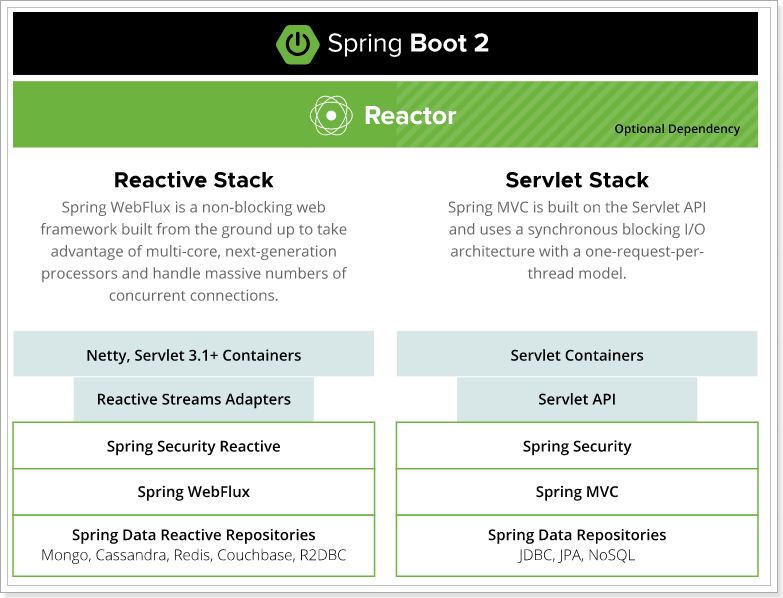
Spring框架中包含的原始Web框架Spring Web MVC是专门为Servlet API和Servlet容器而构建的,是一套同步阻塞的Web应用方案。
响应式Web框架Spring WebFlux在更高版本5.0中添加,它是完全非阻塞的,支持 Reactive Streams、背压,并在Netty,Undertow和Servlet 3.1+容器等服务器上运行。
Spring的Reactive技术栈与传统Servlet技术栈:
3.2.1.为什么需要WebFlux
虽然Servlet3.0也支持异步编程,但是Spring的WebFlux却并不推荐继续使用Servlet容器,而是默认使用Netty,为什么呢?
Spring官网给出的原因有两点:
- Servlet虽然支持异步API,但是其中的
Filter、Listener等组件依然是同步的。而且如getParameter()这样的方法是阻塞的。而WebFlux中使用Netty作为容器,其中的API都是异步或非阻塞式的。 - JDK8中引入了stream的API、函数式编程的新特性。而这些恰好为非阻塞应用和链式编程提供了便捷。而Spring的WebFlux完全支持这些新的特性。
3.2.2.什么是响应式
我们知道什么是非阻塞、函数式编程。那么什么是响应式编程呢?
在传统的编程范式中,我们一般通过迭代器(Iterator)模式来遍历一个序列。这种遍历方式是由调用者来控制节奏的,采用的是拉的方式。每次由调用者通过 next()方法来获取序列中的下一个值。
响应式流采用的则是推的方式,即常见的发布者-订阅者模式。当发布者有新的数据产生时,这些数据会被主动推送到订阅者来进行处理。在响应式流上可以添加各种不同的操作来对数据进行处理,形成数据处理链。
比如,我们调用elasticsearch的异步API,获取一个Future结果,这个结果就是数据的发布者,将来的某一刻会把从elasticsearch中拿到的数据发布出去。
而我们的web应用就可以作为消息的订阅者,订阅elasticsearch的数据,当有数据到来的时候写入response中,响应给用户。
在elasticsearch查询并处理数据的时候,我们的web应用可以去做其它事情,无需阻塞等待,提高CPU利用率
反应式编程最早由 .NET 平台上的 Reactive Extensions (Rx) 库来实现。后来迁移到 Java 平台之后就产生了著名的 RxJava 库,并产生了很多其他编程语言上的对应实现。在这些实现的基础上产生了后来的反应式流(Reactive Streams)规范。该规范定义了反应式流的相关接口,并将集成到 Java 9 中。
3.2.3.Reactor Project
Project Reactor是Java中非常流行的响应式编程库,官网:https://projectreactor.io/
前面提到的 RxJava 库是 JVM 上反应式编程的先驱,也是反应式流规范的基础。不过 RxJava 库也有其不足的地方。
Reactor 则是完全基于反应式流规范设计和实现的库,没有 RxJava 那样的历史包袱,在使用上更加的直观易懂。Reactor 也是 Spring 5 中反应式编程的基础。学习和掌握 Reactor 可以更好地理解 Spring 5 中的相关概念,建议大家以后又机会多多学习该框架。
3.2.4.Flux 和 Mono
Flux 和 Mono 是 Reactor 中的两个基本概念。
Flux 表示的是包含 0 到 N 个元素的异步序列,是一个数据的发布者(publisher)。可以通过subscribe()函数来订阅该发布者的数据。当数据产生时,订阅者的处理方法会执行。
Mono 表示的是包含 0 或者 1 个元素的异步序列。与Flux类似,也是一个数据的发布者(publisher)。
WebFlux的Controller中,业务处理的返回值必须是Mono或者Flux。而我们可以把service或dao中数据查询的过程封装到Mono或Flux中,数据查询成功后由Mono或Flux将数据发布出去。
然后Spring的WebFlux会订阅Mono或Flux数据,接收数据后写入Response,响应给用户
3.3.WebFlux入门
接下来,我们来看看如何构建一个基于WebFlux的web应用。
3.3.1.搭建工程
使用spring的initialize来搭建:
项目名称:
选择依赖:
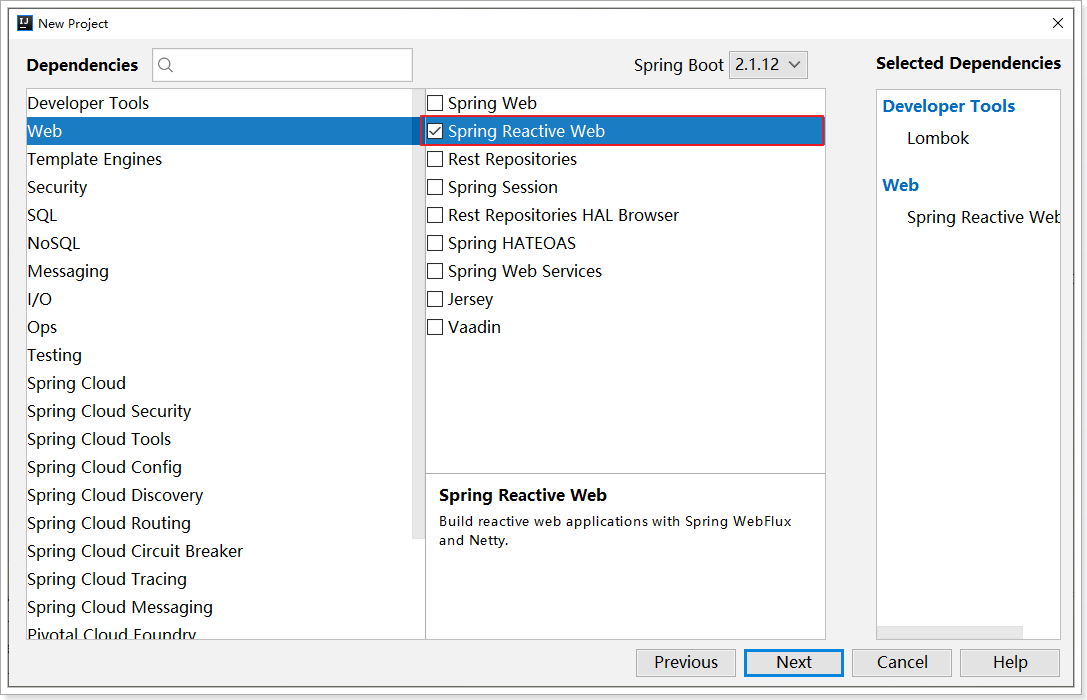
注意,这里必须选择Spring Reactive Web而不是Spring Web依赖。
然后,点击Next完成项目创建。
3.3.2.Mono的Demo
为了降低学习难度,WebFlux开发时可以使用SpringMVC中的注解,因此Controller定义与以前差别不大,来看一个示例.
首先准备一个实体类:
1 | package cn.itcast.demo.pojo; |
1)一个传统的Handler
我们先写一个同步阻塞的Handler:
1 | package cn.itcast.demo.web; |
2)异步的Handler
我们再来写一个异步的Handler:
1 |
|
代码要点:
- 返回值:这里的返回值我们写的是
Mono<User>,是一个只包含一个User元素的Publisher,它会将结果推送给客户端。 Mono.fromSupplier(this::getUser):构建Mono,参数是一个Supplier(无参有返回值的函数式接口),本例中是把getUser()方法作为数据的提供者。
3)测试结果
启动项目,分别访问下面地址:
http://localhost:8080/hello/sync
http://localhost:8080/hello/mono
可以看到控制台的信息:

可以发现,传统的Handler执行getOne()方法,耗时2秒,而Mono方式执行耗时不足1毫秒
3.3.3.Flux的Demo
Mono代表返回值是一个元素,而Flux则代表返回值是一串元素,来看一个示例。
1)普通Flux模式
首先看下基本的Flux模式
1 |
|
这里通过getUserWithFlux()方法生成了包含3个元素的Flux,生成每个元素的间隔是1秒,模拟任务耗时。
来看下页面效果:
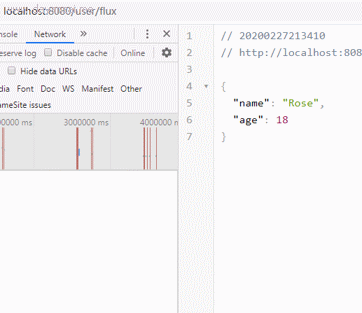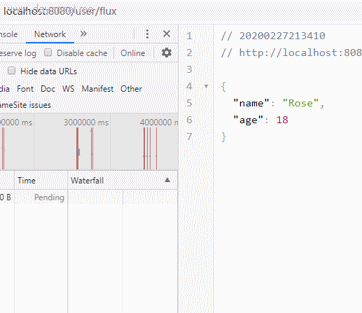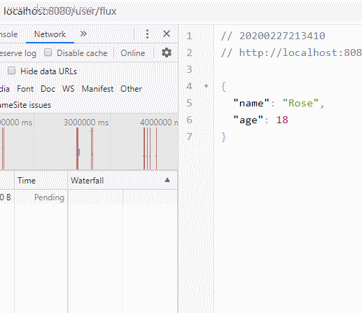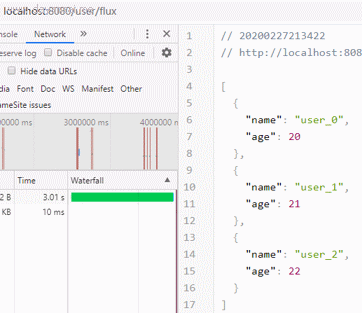
发现在请求发出3秒后,浏览器拿到完整数据,并组织成了一个json的数组
2)通过EventStream格式化的Flux
上面的请求中,响应结果并没有像流一样,逐个返回到页面,而是在3秒后将结果组织为一个JSON数组返回。
如果我们希望数据像流一样,不断生成并返回到页面,我们设置响应模式为:text/event-stream类型。
代码如下:
1 |
|
说明:MediaType.TEXT_EVENT_STREAM_VALUE枚举的值就是text/event-stream
效果图:
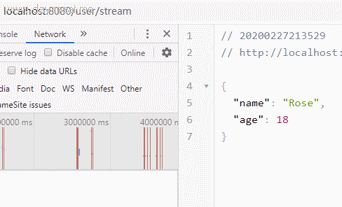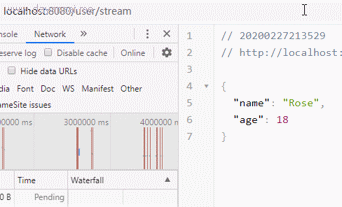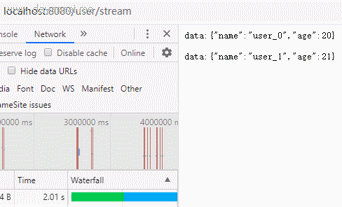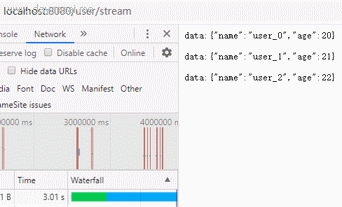
可以看到,请求发出后,数据会逐条返回到客户端,并渲染在页面,真的像数据流一样。最终实现数据从服务端向客户端的持续推送,类似看视频直播一样,这个就是HTML5中的SSE技术:Server Sent Events。
SSE: 服务端到客户端的持续推流,基于http协议
WebSocket:服务端与客户端的双向持续交互,额外的一种协议
3.4.Flux和Mono的API
在WebFlux应用中,我们会的返回值通常都会用Flux或者Mono来封装,那么构建Flux和Mono的方式有哪些呢?
3.4.1.创建Flux的API
1)简单方法
首先是一些简单静态方法,这些方法添加一些包含固定元素的Flux或者简单数字的Flux。包括:
- just():可以指定序列中包含的全部元素。创建出来的 Flux 序列在发布这些元素之后会自动结束。
- fromArray(),fromIterable()和 fromStream():可以从一个数组、Iterable 对象或 Stream 对象中创建 Flux 对象。
- empty():创建一个不包含任何元素,只发布结束消息的序列。
- error(Throwable error):创建一个只包含错误消息的序列。
- never():创建一个不包含任何消息通知的序列。
- range(int start, int count):创建包含从 start 起始的 count 个数量的 Integer 对象的序列。
- interval(Duration period)和 interval(Duration delay, Duration period):创建一个包含了从 0 开始递增的 Long 对象的序列。其中包含的元素按照指定的间隔来生成
代码实例:
1 | // 生成包含两个字符串的Flux:"Hello", "World" |
如果生成元素的逻辑比较复杂,建议使用generate方法或者create方法
2)generate方法
generate()方法通过同步和逐一的方式来产生 Flux 序列。序列的产生是通过调用所提供的 SynchronousSink 对象的 next(),complete()和 error(Throwable)方法来完成的。
代码:
1 | Flux<String> flux = Flux.generate(sink -> { |
这个方法的含义是生成一个Flux,但是只包含一个元素:"hello";
generate()方法的另外一种形式 generate(Callable<S> stateSupplier, BiFunction<S,SynchronousSink<T>,S> generator),其中 stateSupplier 用来提供初始的状态对象。在进行序列生成时,状态对象会作为 generator 使用的第一个参数传入,可以在对应的逻辑中对该状态对象进行修改以供下一次生成时使用。
代码:
1 | // 定义一个随机生成器 |
这个方法的最终结果,是生成一个包含10个随机数的Flux
Generate方法比较抽象,有点类似于reduce方法。如果不好理解,建议使用create方法。
3)create方法
create()方法与 generate()方法的不同之处在于所使用的是 FluxSink 对象。FluxSink 支持同步和异步的消息产生,并且可以在一次调用中产生多个元素。在代码清单 3 中,在一次调用中就产生了全部的 10 个元素。
代码:
1 | Flux<Integer> flux = Flux.create(sink -> { |
3.4.2.创建Mono的API
Mono中只包含一个元素,因此创建起来更加简单,其中包含一些与Flux类似的API:
- just():指定Mono中的固定元素
- empty():创建一个不包含任何元素,但会发送消息的Mono。
- error(Throwable error):创建一个只包含错误消息的Mono。
- never():创建一个不包含任何元素的Mono。
- create():通过MonoSink来构建包含一个元素的Mono,可以使用MonoSink的success()、error()等方法。
代码:
1 | Mono<String> mono = Mono.just("hello"); |
但Mono也有一些独特的方法:
- fromCallable()、fromCompletionStage()、fromFuture()、fromRunnable()和 fromSupplier():分别从 Callable、CompletionStage、CompletableFuture、Runnable 和 Supplier 中创建 Mono。
- delay(Duration duration)和 delayMillis(long duration):创建一个 Mono 序列,在指定的延迟时间之后,产生数字 0 作为唯一值。
- ignoreElements(Publisher
source):创建一个 Mono 序列,忽略作为源的 Publisher 中的所有元素,只产生结束消息。 - justOrEmpty(Optional<? extends T> data)和 justOrEmpty(T data):从一个 Optional 对象或可能为 null 的对象中创建 Mono。只有 Optional 对象中包含值或对象不为 null 时,Mono 序列才产生对应的元素。
代码:
1 | Mono<String> mono = Mono.fromSupplier(() -> "hello"); |